The symptoms of diseases can vary among individuals and may remain undetected in the early stages. Detecting these symptoms is crucial in the initial stage to effectively manage and treat cases of varying severity. Machine learning has made major advances in recent years, proving its effectiveness in various healthcare applications. This study aims to identify patterns of symptoms and general rules regarding symptoms among patients using supervised and unsupervised machine learning. The integration of a rule-based machine learning technique and classification methods is utilized to extend a prediction model. This study analyzes patient data that was available online through the Kaggle repository. After preprocessing the data and exploring descriptive statistics, the Apriori algorithm was applied to identify frequent symptoms and patterns in the discovered rules. Additionally, the study applied several machine learning models for predicting diseases, including stepwise regression, support vector machine, bootstrap forest, boosted trees, and neural-boosted methods. Several predictive machine learning models were applied to the dataset to predict diseases. It was discovered that the stepwise method for fitting outperformed all competitors in this study, as determined through cross-validation conducted for each model based on established criteria. Moreover, numerous significant decision rules were extracted in the study, which can streamline clinical applications without the need for additional expertise. These rules enable the prediction of relationships between symptoms and diseases, as well as between different diseases. Therefore, the results obtained in this study have the potential to improve the performance of prediction models. We can discover diseases symptoms and general rules using supervised and unsupervised machine learning for the dataset. Overall, the proposed algorithm can support not only healthcare professionals but also patients who face cost and time constraints in diagnosing and treating these diseases.


Advancements in healthcare analytics can benefit both doctors and patients, as they can help detect and diagnose diseases early on, ultimately improving healthcare quality and patient outcomes. The use of Machine Learning (ML) techniques to predict disease symptoms in patients is both promising and challenging in the field of Artificial Intelligence (AI). AI enables the analysis of vast medical datasets, enhancing diagnostics, predicting disease outcomes, and optimizing treatment plans. AI methods can discover patterns in patient data, aiding in early detection of illnesses and personalizing medical interventions. Additionally, AI contributes to operational efficiencies, streamlining administrative tasks and improving resource allocation. The continuous evolution of AI in healthcare analytics holds great promise for improved decision-making, patient outcomes, and overall healthcare system optimization. The reliability of AI has significantly benefited medical diagnostics in the modern era. AI has extended the capabilities of human vision, and utilized in medical research.
The application of ML in discovering diseases symptoms has the potential to revolutionize diagnostics, treatment, and patient care, but further research and development are needed to overcome the existing challenges. Some ML algorithms have been used in healthcare field to predict different diseases like heart disease 1 . Additionally, Association Rules (AR) have been employed for knowledge extraction. These algorithms analyze data to identify patterns and make predictions, offering the use of ML techniques in predicting disease symptoms among patients has the potential to enhance patient outcomes, and enhance the efficiency of the health centers 2 . Despite the potential benefits, the integration of ML in healthcare is still in its infancy, and there are several challenges to overcome before widespread adoption can occur primarily due to the lack of user-friendly ML systems that cater to non-technical users. Therefore, the development of a model or system that facilitates the diagnosis of diseases using ML techniques is a promising and challenging aspect of AI. With this objective in mind, we have conducted a study to establish an AI-based methodology for the initial diagnosis of these symptoms. The application of ML algorithms has been evident in numerous recent healthcare works 3 . Several literature reviews have been conducted on the use of ML algorithms in diagnosing diseases. These reviews cover a comprehensive range of diseases and the application of various ML techniques for disease diagnosis. The research work 4 conducted a comprehensive review of ML-based disease diagnosis, examining the most recent trends and approaches in ML for disease diagnosis. Some of the main findings from these reviews include the use of ML algorithms like Naïve Bayes, Support Vector Machine (SVM), K Nearest Neighbor (KNN), and Random Forest (RF) for disease diagnosis 5 . Also, the authors of 6 focused on the most common ML methods applied to extend AI applications, including neural networks, SVM, ANN, RF, Decision Trees (DT), Logistic Regression (LR), and Neural-boosted (NB). Woodman and Mangoni 7 also discussed the growing application of ML in diagnosing both common and rare diseases. Additionally, Poudel 8 provided a perfect overview of the most frequently used ML algorithms in disease diagnosis, along with a focus on the clinical challenges involved in relying on these algorithms. Furthermore, the research 9 highlighted the benefits, methodologies, and functionalities of using ML algorithms in disease diagnosis in the healthcare sector. Ferdous et al. 10 provided a literature survey on them in healthcare with the best accuracy in diagnosing diseases. Fatima and Pasha 11 highlighted the advantages and disadvantages of these methods and provided a comparative analysis of different ML techniques for disease diagnosis. Overall, these literature reviews offer valuable insights into the use of ML algorithms for disease diagnosis and provide a comprehensive understanding of the current trends and future research directions.
Supervised ML algorithms demonstrate impressive results when dealing with well-labeled datasets, and they are widely employed in various fields. The application of supervised ML in healthcare analytics empowers clinicians, administrators, and policymakers to make data-driven decisions, enhance patient care, and optimize healthcare delivery 12 . Supervised ML plays a pivotal role in healthcare analytics too, particularly in predictive modeling. In healthcare, Supervised ML methods can be used to identify diseases and diagnose them, predict patient outcomes, and optimize treatment plans. Predictive modeling in supervised ML algorithms is the process of building a model that can predict future outcomes using historical data. After the in-depth search, Kumar et al. 13 found that 85% of the supervised learning methods characterized the study, while the remaining 15% were characterized by unsupervised learning methods. In this regard, the Flores et al. 14 surveyed the application of unsupervised ML methods in discovering latent disease clusters using electronic health records. The authors used Latent Dirichlet Allocation, and suggested a new model named Poisson Dirichlet model. The research effort 15 showed that K-Mean and SVM have also diagnosed and evaluated diabetes as an amalgamation of supervised and unsupervised ML techniques. In addition, Lim et al. 16 provided an unsupervised ML model for discovering latent infectious diseases using social media data. The research 17 focused on an unsupervised ML algorithm for detecting patient clusters using genetic signatures. The authors could assign high-risk and chronic disease patients into a detected cluster using their genomic makeup. The study by Bose and Radhakrishnan 18 employed unsupervised ML techniques to categorize patients with heart failure who utilized telehealth services in the home health setting. The researchers analyzed the differences between these subgroups in terms of patient characteristics, such as symptoms.
Predictive analytics is used to forecast future events by examining the correlation between input and output variables. The increasing availability of electronic clinical data in the U.S. healthcare system has led to the growing popularity of predictive systems in healthcare 19 . Some common predictive algorithms include ML and deep learning, which are subsets of AI. These algorithms use historical data to train algorithms that can predict future outcomes. For example, predictive models help assess the risk of patient readmission. Hospitals can use predictive analytics to estimate the length of a patient’s hospital stay. This aids in resource planning, bed management, and improving overall operational efficiency. On the other hand, predictive modeling is applied to identify fraudulent activities in healthcare billing too. Also, physicians can benefit from predictive models that offer insights into potential diagnoses based on patient data. Besides, predictive models are utilized to forecast the likelihood of diseases and adverse events. These models can analyze patient data to predict the likelihood of developing diseases symptoms 20 . Unsupervised learning and predictive modeling are both important techniques in ML, each serving different purposes in data analysis and pattern recognition.
In unsupervised learning, the model works on its own to discover patterns and information in unlabeled data. AR learning is a type of unsupervised learning that investigates for the dependency of one data item on another and is used to extract hidden patterns from data. Additionally, AR mining can empower clinicians to make quick and automatic decisions, extract valuable information. The study’s findings are crucial for understanding disease symptoms, which is critical in initial triage to distinguish the severity of cases. Hence, this study aims to use AR mining to identify symptom in the patients and explore these patterns based on explanatory variables. Some notable papers on AR in healthcare. For the first time, Brossette et al. 21 discussed the use of AR for discovering new patterns in hospital infection control and public health surveillance data. The authors proposed a process for analyzing surveillance data by comparing their confidences across different data partitions. The study of 22 used AR mining to extract hidden patterns and relationships between diagnostic test requirements in real-life medical data. After that, Happawana et al. 23 explored the use of AR mining techniques for generalizing diagnoses from a public health dataset based on techniques for reducing the search space. Additionally, Miswan et al. 24 presented a case study on using AR mining to analyze hospital readmission data. The authors discussed various related studies and techniques, such as data mining for hospital readmission. In COVID-19 epidemic, Tandan et al. 25 discovered symptom patterns of COVID-19 patients using AR mining. In a similar way, the symptom patterns of COVID-19 from recovered and deceased patients are extracted by work 26 using Apriori AR mining. In another view point, Khafaga et al. 27 constructed a prediction system for predicting diabetes by AR algorithm. More recently, Cui et al. 28 proposed the weighted Apriori algorithm for discovering AR from disease diagnostic data. The authors also designed an improved KNN algorithm as a pre-step to obtain more accurate associations on a higher level.
Now, we perform a detailed comparison of this work with the relevant prominent studies in the field of hybrid supervised and unsupervised ML. As a pioneer, Péran et al. 29 focused on the classification of Parkinson’s disease and multiple system atrophy using supervised and unsupervised learning techniques applied to MRI data. After that, Ma et al. 30 leveraged the phenotyping structure using the integrated of unsupervised and supervised ML methods for phenotyping complex diseases with a unique application. Also, Cai et al. 31 presented an approach that combines unsupervised and supervised learning techniques to detect self-reported COVID-19 symptoms on Twitter. More recently, Sáiz-Manzanares et al. 32 explored the application of supervised and unsupervised ML techniques in therapeutic interventions for children. In comparison to these existing methodologies, our study aims to identify patterns of symptoms and general rules regarding symptoms among patients using a combination of supervised and unsupervised ML techniques. This study utilizes the Apriori algorithm to identify frequent symptoms and patterns, which is a unique approach compared to the other studies. In other words, the study integrates a rule-based ML technique and classification methods to extend a prediction model. This approach is different from the studies that focus on a single algorithm or a specific type of disease. Additionally, our study applies several ML models, including Stepwise Regression (SR), SVMs, Bootstrap Forest (BF), Boosted Trees (BT), and NB methods, to predict diseases, demonstrating the versatility of our approach.
To the best of our knowledge, there is no work to utilize supervised and unsupervised ML algorithms to extract the common symptoms of the mentioned diseases. As aforementioned it is necessary to extend an integrated diagnosis system of diseases using a suite of AI. In summary, our approach is distinct from other studies in several ways:
Therefore, this paper aims to model and predict disease symptoms using classification and AR methods. In this regard, we distinguish the most significant risk variables and the correlation between them after data preparation. Moreover, we compare the predictive performance of a range of different ML models to determine the best solution for diseases symptoms diagnosis. Also, AR mining has been used to extract symptom patterns of the diseases set to conduct intelligent diagnosis by extract valuable rules in this paper. The remainder of this paper is structured as follows: Section “Methodology” discusses related work. Section “Results” presents the details of the research methodology and dataset. Section “Conclusion and future research” covers the results and discussion. In the final section, we conclude the study with objectives, limitations, and research contributions.
The proposed method is given in this section. The main goal is to exploring the relationship that exist between the disease symptoms and implement different types of ML techniques in discovering diseases symptoms to predict the diseases. In this regard, the proposed methods of supervised and unsupervised ML are explained for discovering diseases symptoms. The selection of algorithms was based on a thorough review of the literature and consideration of the specific research question and data characteristics. For supervised learning, we chose to use linear regression, SVMs, BF, BT, and NB methods because these algorithms have been widely used and shown to be effective in predicting diseases in various studies 4 . For unsupervised learning, we chose to use the Association rule algorithm because it is a well-established method for discovering frequent patterns and rules in data 21,22,23,24,25,26,27,28 . The Apriori algorithm is particularly useful for identifying patterns in large datasets and can be used to identify both frequent and rare events. Additionally, the Apriori algorithm can be used to identify patterns that are not necessarily linear or continuous, making it a useful tool for identifying complex relationships in data. We believe that the combination of these algorithms provides a comprehensive approach to identifying patterns of symptoms and general rules regarding symptoms among patients. The use of multiple algorithms allows us to leverage the strengths of each method and to identify patterns that may not be apparent using a single algorithm.
The study leverages a combination of programming languages and libraries to facilitate data analysis and ML tasks. Specifically, JMP scripting language, JMP data tables, and JMP modeling and ML are employed to streamline data preprocessing, model training, and evaluation. The data preprocessing process involves several key steps, including data import, data cleaning, and data transformation. Furthermore, the model training and evaluation phases utilize a range of techniques, including model screening, association analysis, model training, and model evaluation. Additionally, various tools are utilized, such as JMP modeling and ML and JMP association analysis, to support these tasks.
The approach starts with a data preparation, and the AR method. Then, classification algorithms are used and compared with each other to predict disease models. Figure 1 is a schematic overview of the proposed approach. The following subsections present the dataset description and data preparation, applied unsupervised and supervised ML methods as well.
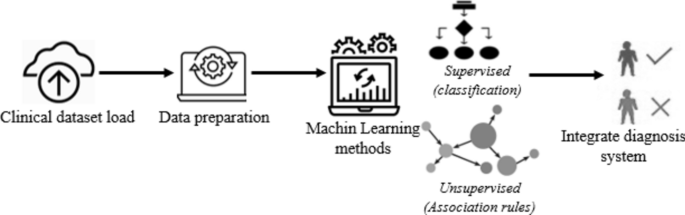
Firstly, this subsection goes into the specifics of the disease dataset that was utilized, and then data preprocessing is performed in this research. Our dataset provides a comprehensive compilation of symptoms and patient profiles for a range of diseases. The mysteries of diseases can be unveiled with this disease symptom and patient profile dataset. The analytic results can show intricate relationship between patients and diseases. In other words, the proposed system can assist in the extracting the AR and development of predictive models for disease diagnosis and monitoring based on symptoms and patient characteristics. On this subject, we utilized an available online data set by the Kaggle Repository. In our study, we used a publicly available Kaggle dataset that does not contain personally identifiable information (PII). To handle the sensitive health data responsibly, we consider ensured data anonymization and maintained compliance with data privacy regulations, such as HIPAA and GDPR. By taking these measures, we aim to protect the privacy and confidentiality of the patient information, comply with relevant data protection regulations, and conduct the research in an ethical and transparent manner, prioritizing the rights and well-being of the study participants. The dataset offers a detailed examination of the intricate relationships between patients and diseases, comprising over 100 distinct medical conditions and featuring 3490 records. The dataset offers a treasure trove of information including fever, cough, fatigue, and breathing difficulty, intertwined with age, gender, blood pressure, and cholesterol levels revealing the fascinating connections between symptoms, demographics, and health indicators. We aim to explore the hidden patterns, and uncover unique symptom profiles. The dataset has 10 attributes, which are given in Table 1.

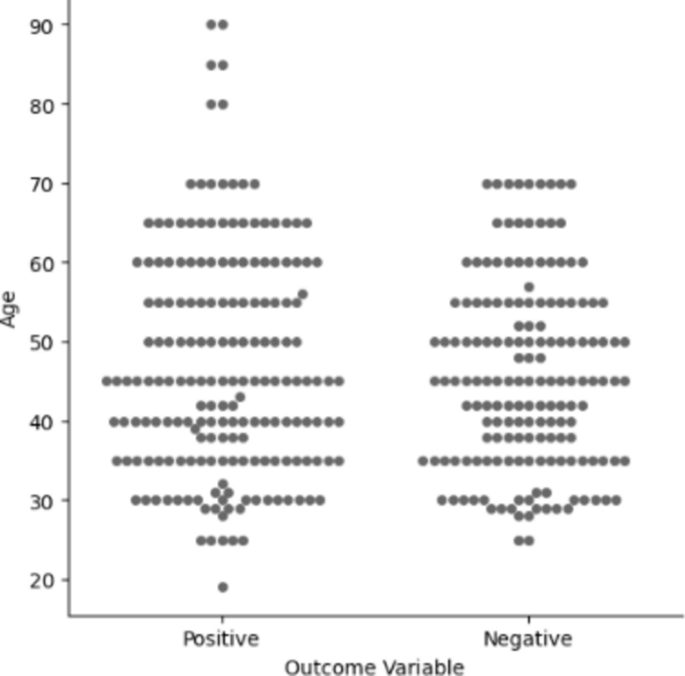
After data preparation phase, we perform a descriptive statistical analysis to help more ML methods. Some of these investigations are provided here. In this regard, the dataset does not exhibit significant skewness, with only a few outliers present, and the gender distribution in the dataset is relatively balanced. Figure 3 shows that individuals have a higher likelihood of testing positive for diseases, in older age. Additionally, Fig. 4 shows fever is a main symptom of these diseases. This figure demonstrates many individuals, regardless of the type of experience (positive or negative), report coughing.
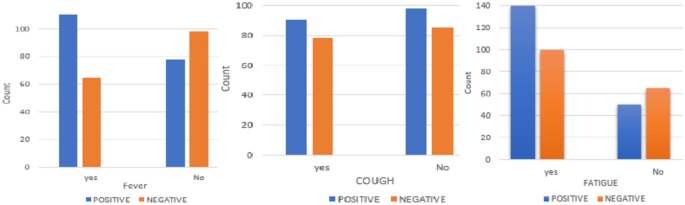
The more analytics using pie chart shows the majority of the individuals in the study have high blood pressure and cholesterol. Additionally, out of 348 patients, 185 tested positive for a disease. Only 23 of the positive cases developed all symptoms. The average age of the patients is 46, with the majority being middle-aged. However, positive cases are proportionally higher in older adults. A violin plot indicates that older adults have high blood pressure, but older adult to middle-aged patients also exhibit high blood pressure. The most common symptoms were fatigue (139 cases), fever (109 cases), breathing difficulty, and cough (both seen in 88 cases). Females are more prone to the diseases than Males.
We used an a Apriori method to extract lift matrix-based strong rules. Symptom transactions are part of the AR mining which aims to identify frequent item sets that meet a minimum threshold. To achieve this, we set the minimum confidence level to 1, ensuring that all generated rules have a 100% confidence level. Additionally, we establish a minimum support threshold above 0.01 and a lift greater than 4 for positively correlated rules. This means that the rules generated must have a support value greater than 1% and a lift value greater than 4, indicating a strong positive correlation between the antecedent and consequent items. Furthermore, we limit the maximum number of antecedents to 3 and the maximum rule size to 4, ensuring that the generated rules are concise and interpretable. To do so, we discover many significant AR for the data, and the top 20 symptom rules by highest lift values are given in Table 2. Table 2 concentrates on the antecedents (diseases) associated with the consequents (symptoms) to predict asymptotes of diseases.
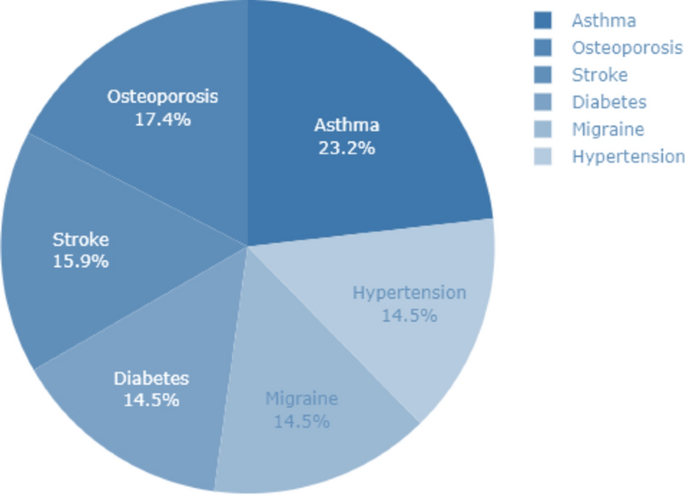
The pie chart shows that the classes are imbalanced, and we need to handle class imbalance. Before that, we need to process our categorical variables to perform a univariate analysis. This analysis will help us understand the distribution of our variables and their individual impact on disease prediction. We will start with the age variable, followed by other variables like symptoms, gender, blood pressure, and cholesterol level.
The univariate analysis of the age variable in Fig. 7 reveals that age is a valuable feature for predicting certain diseases. For instance, if the age is greater than 80, the disease is likely to be a stroke. However, the dataset has limited samples, especially for ages greater than 80, which could make predicting new values in this age range challenging. The analysis also shows that some diseases like Migraine and Hypertension are not present in ages between 20 and 30, suggesting that these conditions are more prevalent in older age groups. Hypertension and Osteoporosis appear more frequently as the age increases, indicating a potential correlation between these diseases and age. Also, cholesterol levels and blood pressure, significantly influence disease prediction. For example, High blood pressure is associated with the absence of stroke, which is crucial for stroke prediction. These observations emphasize the importance of these variables in predicting diseases. The next step is to examine how these variables correlate with each other, which can help identify patterns and potential multicollinearity, ultimately influencing the model’s performance.
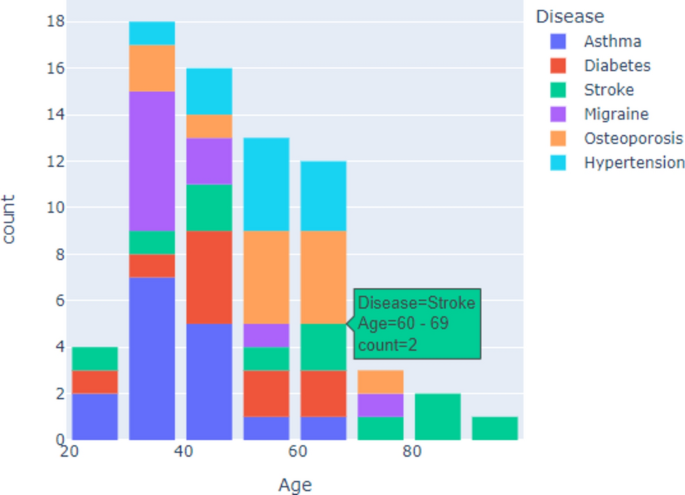
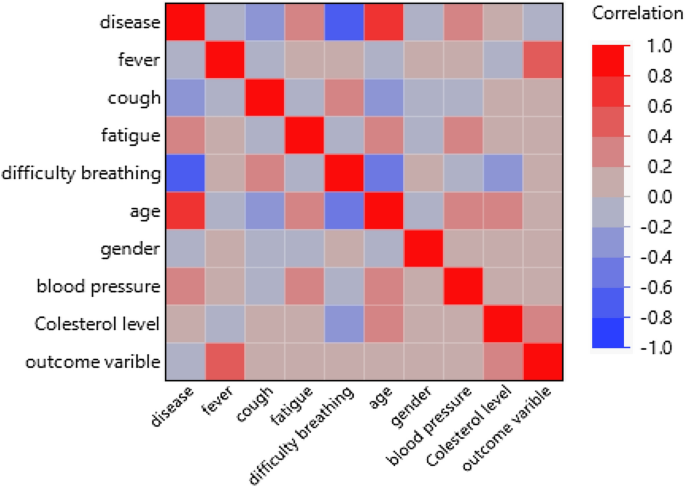
Figure 8 shows that none of the variables have a strong correlation with the “Disease” variable. The most correlated variables are “Age” and “Difficulty Breathing”, with scores of 1 and − 1, respectively. In situations where there are multiple variables with high correlation scores, ML can be a viable alternative for prediction tasks. However, it’s essential to consider that ML algorithms, typically require large amounts of data to perform optimally. In our case, we have only 79 data points, which is relatively small.
For hyperparameter tuning, we used the Grid Search method in JMP. Grid search is a simple and effective method for finding the optimal combination of hyperparameters by systematically varying each hyperparameter over a range of values and evaluating the performance of the model at each combination. We used a grid search with 10 iterations to find the optimal combination of hyperparameters for each model. For example, for the SR, we used a grid search to optimize the following hyperparameters:
For the SVMs, we used a grid search to optimize the following hyperparameters:
For the BF model, we used a grid search to optimize the following hyperparameters:
For the BT model, we used a grid search to optimize the following hyperparameters:
For the NB methods, we used a grid search to optimize the following hyperparameters:
To conduct a fair comparison between different classifiers and identify the superior model with the best performance, we have considered and calculated several evaluation metrics that are well-suited for our specific case and dataset. The evaluation metrics we have included are:
$$ > = \frac <<\left(